Lost in the rabbit hole of Google Takeout
| Anke (encarsia) | Also available in: Deutsch
Contents
Backup your data. They said. All of it. They said. And then came Google Takeout
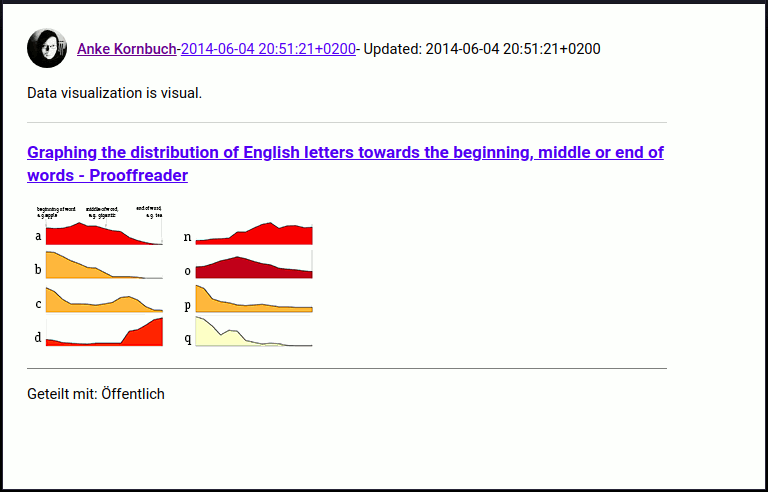
G+ post HTML file from Takeout
I get the 4, 20 and Google+
Takeout is Google's user data archive system for numerous products. My primary target me was to download an archive of my Google+ activities.
The approach is quite simple: choose the product in Takeout and wait until the archive(s) has/have been generated. The downloadable archive will be valid for a week but you can generate new archives at any time.
- Lesson 1:
-
Choose zip as filetype if you use umlauts, there could be encoding issues in tgz files.
I remembered that there was an import plugin for Nikola and I imagined to throw in the archive and to get a usable local site in return. At this point of the article the reader may speculate that this didn't work in the slightest way.
Unpacking presents
The first inspection reveals:
All G+ posts are located in
Google+ stream/Postsas HTML files. These files appear usable.Image links just point to filenames. The path is missing so only images in the same directory are shown but
Images are scattered among different directories (in
PostsandPhotosand their subfolders). The majority of image files are stored inPhotos of postsin date corresponding subfolders.There are different date formats in peaceful co-existence:
Photos of posts/ ├── 02.06.14 ├── 02.06.16 ├── 22. Juli 2013 ├── 23.01.17 ├── 2011-08-14 └── 2012-03-13
There is a corresponding JSON file for every image but not for HTML files.
Strucure of HTML files:
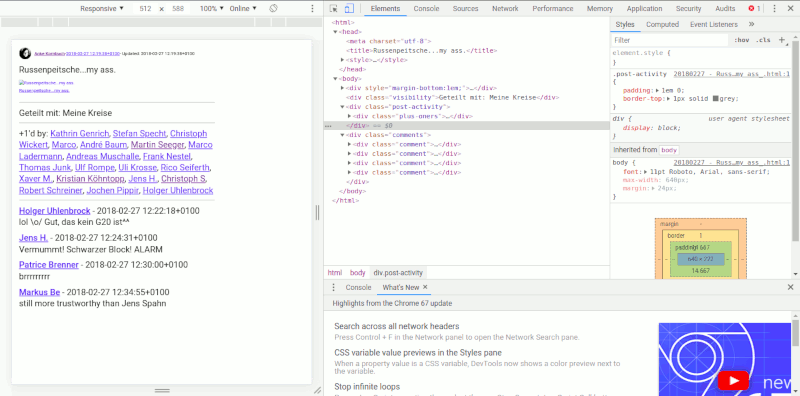
Dumdidumdumdum...Inspektor Gadget
- Lesson 2
-
You can open only single posts, there are a lot of deadlinks in image posts, but share and reaction information are displayed (public/private/collection/community post, +1, reshares and comments).
Your entry: Nikola
With low expectations I install the import plugin for Nikola and see what happens. Nothing. The posts once were provided as JSON files but not in recent days.
I brachiate through the files, importing HTML files first. The import plugin instantiates a new Nikola site, so I can just trial and error like hell. Then I care about deadlinks, then titles, it kepps getting better with every build.
The result is a static website of my Google+ stream including +1's and comments and a link to the original post.
Theming
In general the import is independent from any theme. I personally recommend hyde which even can be improved by the custom.css that is included in the archive.
Wishlist
local search function
filter posts by share status
Attention!
In case you consider a publicly accessible stream backup you have to keep in mind that the imported data also includes all privately shared posts.
Conclusion
As a long-term heavy Google+ user you are used to inconsistencies and improvementent constantly getting worse so a Takeout archive is no more than a sparring partner to train with. It is only a matter of time until my version of the import plugin will go the way of all those Google messengers before.
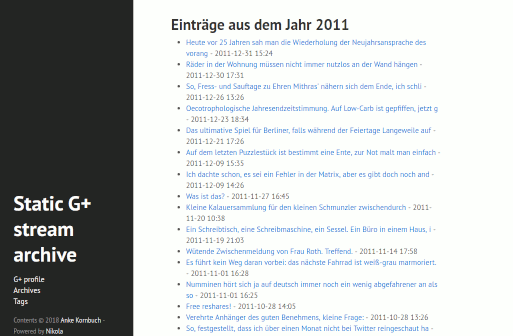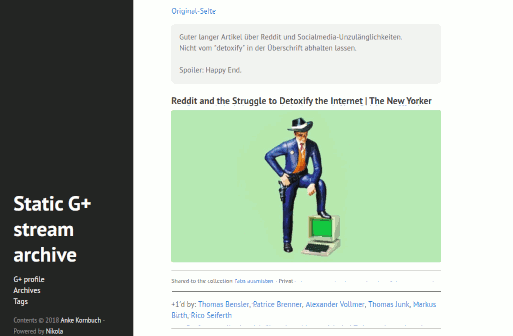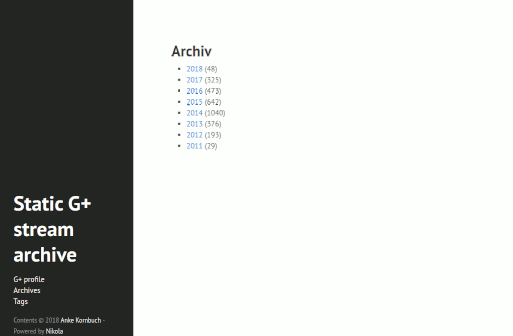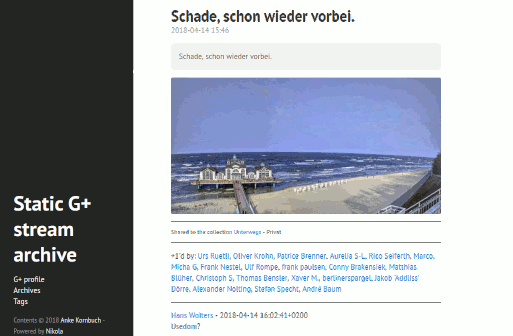
static Google+ Nikola site (hyde theme)
Update
The end of Google+ has been recently announced and the issue of backing up and presentation of the data has become more relevant.
You can download the plugin now from GitHub: encarsia/gplus_nikola_import.
The associated article to the plugin: Nikola-Import-Plugin für Google+ (currently only in German but there is a detailed README file in the repository on how to get the plugin work).
Comment on
Comments
Comments powered by Disqus