Verloren im Kaninchenbau von Google Takeout
| Anke (encarsia) | Auch verfügbar in: English
Inhalt
Mach Backups deiner Daten. Habensegesagt. Aller Daten. Habensegesagt. Und dann kam Google Takeout
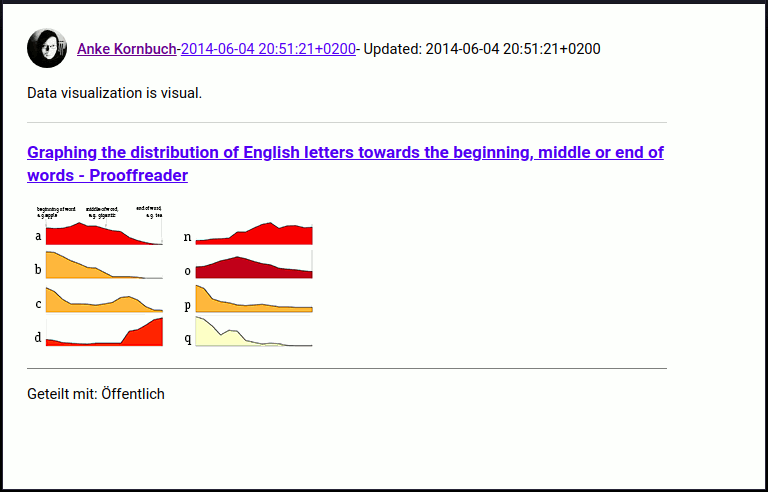
G+-Post-Ansicht von Takeout
Die 4, die 20 und Google+, alles zum Mitnehmen
Takeout nennt sich Googles Archivsystem für allerlei Produkte aus dem Hause Alpha. Das Primärziel bestand darin, ein Archiv meiner Google+-Aktivitäten herunterzuladen.
Dies gestaltete sich zunächst recht einfach: das Archiv (bzw. (je nach Größe) die Archive) wird erstellt. Bei Fertigstellung erhält man eine Nachricht mit Downloadlink. Das Archiv verfällt nach einer Woche, aber man kann jederzeit neue erstellen.
Lektion 1
Wähle als Dateiformat zip, tgz könnte Encoding-Probleme mit Umlauten haben (Dies ist keine Übung!).
Ich erinnerte mich dunkel daran, dass ein Import-Plugin für Nikola existierte und malte mir aus, das Archiv einfach dort abzuwerfen und eine halbwegs nutzbare lokale Seite gebaut zu bekommen. Der geneigte Leser wird bereits an dieser Stelle mutmaßen, dass dieser Ansatz nicht funktionierte.
Geschenke auspacken
Nach ersten Untersuchungen zeigen sich folgende Fakten:
Alle G+-Beiträge befinden sich in
Stream in Google+/Beiträgeals HTML-Dateien. Diese sehen zunächst brauchbar aus.Enthaltene Bildverweise geben nur den Dateinamen an, der fehlende Dateipfad lädt demzufolgge nur Bilder im selben Verzeichnis, aber
Bilder befinden sich in diversen Unterverzeichnissen, sowohl in
Beiträgeals auch inFotosund deren Unterverzeichnissen. Die Mehrheit befindet sich inFotos von Beiträgen, dort jeweils in Datumsunterverzeichnisse einsortiert.Ein Datumsformat ist so gut wie jedes andere und so findet man dort in friedlicher Koexistenz Dinge wie:
Fotos von Beiträgen/ ├── 02.06.14 ├── 02.06.16 ├── 22. Juli 2013 ├── 23.01.17 ├── 2011-08-14 └── 2012-03-13
Fotos haben eine dazugehörige JSON-Datei, HTML-Dateien nicht.
Die Inspektion der HTML-Dateien ergibt eine übersichtliche Struktur mit Klassenangabe.
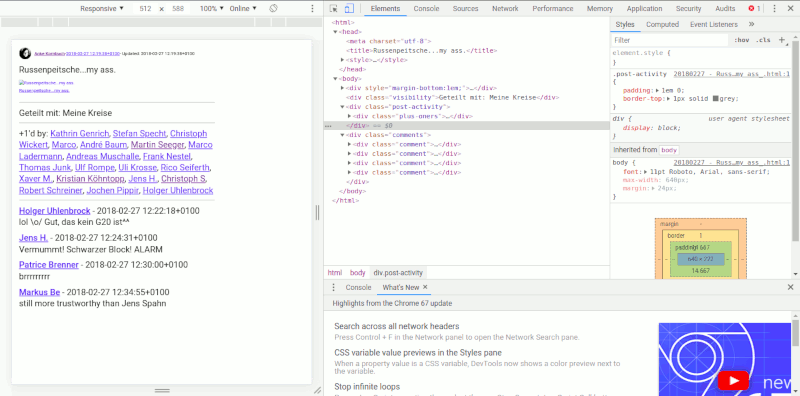
Dumdidumdumdum...Inspektor Gadget
Lektion 2
Beiträge lassen sich nur einzeln aufrufen, es gibt jede Menge Deadlinks bei Bilderposts, aber immerhin sieht man den Verteilungstatus (öffentlich, Sammlung, Community), +1, Reshares und Kommentare.
Auftritt: Nikola
Mit leicht getrübten Erwartungen installiere ich das Import-Plugin für Nikola und lege los. Es passt gar nichts. Angeblich stehen die Beiträge auch als JSON zur Verfügung. Das war bestimmt auch einst so, jetzt nicht mehr.
Ich hangele mich an den Dateien entlang, importiere zunächst die HTML-Dateien. Das Import-Plugin erstellt grundsätzlich eine neue Nikola-Seite, so dass man hier nach Gusto wüten kann. Dann kümmere ich mich um die Deadlinks. Dann die Titel - ich bin wie im Rausch: mit jedem Build wird es besser.
Das Ergebnis ist eine statische Webseite meines Google+-Streams inklusive Plussen und Kommentaren. Man kommt von den Beiträgen immer zum Originalbeitrag.
Eyecandy
Grundsätzlich funktioniert der Import themenunabhängig. hyde liefert ein schönes Ergebnis, etwas nachgeholfen wird mit der custom.css.
Wünsch dir was
eine lokale Suchfunktion wäre schön
gefilterte Anzeige je nach Verteilungsstatus
Achtung!
Plant man ein öffentlich einsehbares Backup des Streams, ist zu beachten, dass der Import auch private Beiträge enthält.
Fazit
Als langjähriger Google+-Nutzer ist man auf Inkonsistenzen und Verschlimmbesserungen konditioniert, da kommt Takeout als Sparringspartner nur gelegen. Es ist nur eine Frage der Zeit, bis auch diese Plugin-Version den Weg jedes Google-Messengers gehen wird.
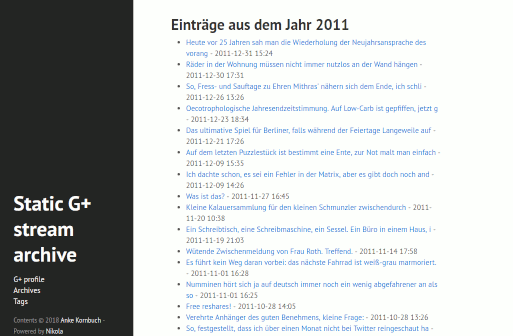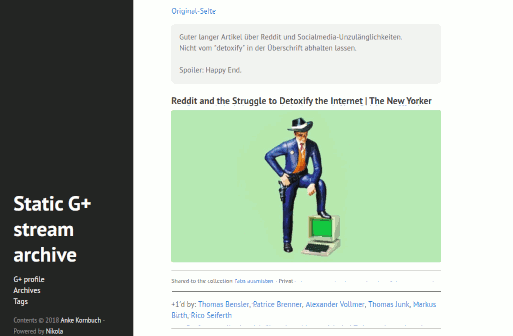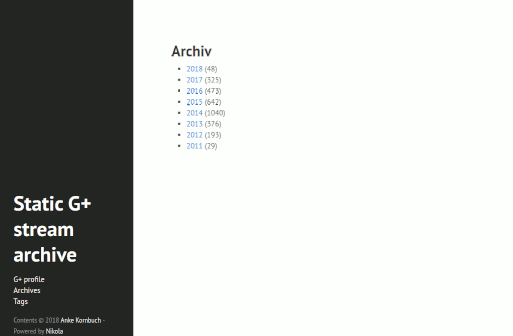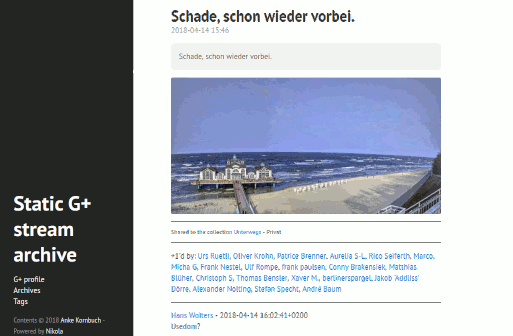
Resultat der Nikola-generierten Seite mit hyde-Thema
Update
Inzwischen wurde die Einstellung von Google+ angekündigt und die Frage nach Backups und Aufbereitung der Daten relevant.
Das Plugin kann man nun bei GitHub herunterladen: encarsia/gplus_nikola_import.
Den dazugehörigen Artikel gibt es hier: Nikola-Import-Plugin für Google+.
Kommentieren auf
Kommentare
Comments powered by Disqus